VSI DECset for OpenVMS Guide to Detailed Program Design
- Software Version:
- DECset Version 12.8 for OpenVMS
- Operating System and Version:
- VSI OpenVMS x86-64 Version 9.2-2 or higher
VSI OpenVMS IA-64 Version 8.4-1H1 or higher
VSI OpenVMS Alpha Version 8.4-2L1 or higher
Preface
This guide introduces the Program Design Facility, which provides an integrated method for designing, creating, compiling, correcting, and inspecting source code. The guide also explains how to get started using its basic features.
1. About VSI
VMS Software, Inc. (VSI) is an independent software company licensed by Hewlett Packard Enterprise to develop and support the OpenVMS operating system.
2. Intended Audience
This guide is for experienced programmers and technical managers involved in detailed program design. The user should be familiar with both LSE and SCA.
3. Document Structure
Chapter 1, "Introduction" provides an overview of the VSI DECset tools, LSE, SCA, and program design.
Chapter 2, "Getting Started Designing Programs" shows how features of LSE, SCA, and OpenVMS compilers are used to design programs and generate reports.
Chapter 3, "Entering Design Information Using LSE" provides in-depth information on entering detailed program design.
Chapter 4, "Retrieving Design Information" provides information on running standard reports, the available options, and sample outputs for each report.
Chapter 5, "Customizing Reports" provides information on customizing reports and creating new reports.
4. Related Documents
Using VSI DECset for OpenVMS Systems describes how to use the Software Engineering Tools (VSI DECset) with other OpenVMS facilities to create an effective software development environment on OpenVMS systems.
VSI DECset for OpenVMS Guide to Language-Sensitive Editor contains instructions on how to use the DECwindows LSE.
VSI DECset for OpenVMS Language-Sensitive Editor/Source Code Analyzer Reference Manual contains command dictionary, parameter glossary,command summary and translation table information for both the LSE and SCA components.
VSI DECset for OpenVMS Language-Sensitive Editor Command-Line Interface and Callable Routines Reference Manual contains LSE command-line interface information and OpenVMS-specific information.
VSI DECset for OpenVMS Guide to Source Code Analyzer contains instructions on how to use the DECwindows SCA.
VSI DECset for OpenVMS Source Code Analyzer Command-Line Interface and Callable Routines Reference Manual contains SCA command-line interface information and OpenVMS-specific information.
5. References to Other Products
Note
These references serve only to provide examples to those who continue to use these products with DECset.
Refer to the Software Product Description for a current list of the products that the DECset components are warranted to interact with and support.
6. OpenVMS Documentation
The full VSI OpenVMS documentation set can be found on the VMS Software Documentation webpage at https://docs.vmssoftware.com.
7. VSI Encourages Your Comments
You may send comments or suggestions regarding this manual or any VSI document by sending electronic mail to the following Internet address: <docinfo@vmssoftware.com>. Users who have VSI OpenVMS support contracts through VSI can contact <support@vmssoftware.com> for help with this product.
8. Typographical Conventions
|
Convention |
Description |
|---|---|
|
$ |
A dollar sign ($) represents the OpenVMS DCL system prompt. |
|
Ctrl/x |
The key combination Ctrl/x indicates that you must press the key labeled Ctrl while you simultaneously press another key, for example, Ctrl/Y or Ctrl/Z. |
|
KPn |
The phrase KPn indicates that you must press the key labeled with the number or character n on the numeric keypad, for example, KP3 or KP-. |
|
file-spec, ... |
A horizontal ellipsis following a parameter, option, or value in syntax descriptions indicates additional parameters, options, or values you can enter. |
... |
A horizontal ellipsis in a figure or example indicates that not all of the statements are shown. |
. . . |
A vertical ellipsis indicates the omission of items from a code example or command format; the items are omitted because they are not important to the topic being described. |
|
( ) |
In format descriptions, if you choose more than one option, parentheses indicate that you must enclose the choices in parentheses. |
|
[ ] |
In format descriptions, brackets indicate that whatever is enclosed is optional; you can select none, one, or all of the choices. |
|
{ } |
In format descriptions, braces surround a required choice of options; you must choose one of the options listed. |
|
bold text |
Bold text represents the introduction of a new term. |
|
italic text |
Italic text represents book titles, parameters, arguments, and information that can vary in system messages (for example, Internal error number). |
|
UPPERCASE |
Uppercase indicates the name of a command,routine, file, file protection code, or the abbreviation of a system privilege. |
|
lowercase |
Lowercase in examples indicates that you are to substitute a word or value of your choice. |
Chapter 1. Introduction
This chapter is an introduction to the Software Engineering Tools (VSI DECset), designing programs, and generating reports.
The Program Design Facility provides an integrated method for designing, creating, compiling, correcting, and inspecting source code. This is not a product, or even a tool—it is an abstract title for a set of features implemented across Language-Sensitive Editor (LSE), Source Code Analyzer (SCA), and the compilers.
1.1. VSI DECset
The DECset tools provide an integrated method for designing, creating,compiling, correcting, and inspecting your source code. You can include design information that can be processed, analyzed, and preserved throughout the software development cycle. You can review and modify the source code for your software project, and access all your project files through LSE.
Language-Sensitive Editor/Source Code Analyzer (LSE/SCA)
Code Management System (CMS)
Module Management System (MMS)
VSI Digital Test Manager
Performance and Coverage Analyzer (PCA)
DECset Environment Manager
The combination of features from two of these tools, LSE and SCA, provide the ability to design programs and retrieve program design.
Support for the multiple phases of the software life cycle
Support for applications written in multiple languages
Compilers and tools that pass substantial information among themselves to automate tasks previously performed manually
1.2. Source Code Analyzer (SCA)
The Source Code Analyzer (SCA) is an interactive cross-reference and static analysis tool that works with many languages. It can help you understand the complexities of a large software project. Because it allows you to analyze and understand an entire system, SCA is extremely useful during the implementation and maintenance phases of a project.
Cross-referencing—Gives you an index to information in your source code
Static analysis—Enables you to extract information about program structures and the relationship of routines, symbols, and files
Library creation and maintenance—Takes the information generated by supported compilers and merges these files together into libraries to create a picture of your entire project
Graphical user interface—Provides a DECwindows-based user interface from which you can easily access all SCA capabilities
1.3. Language-Sensitive Editor (LSE)
Code compilation
Diagnostic review
Formatted language constructs
Online language HELP
Pseudocode entry support
Code outlining
Documentation extraction
With LSE, you can customize your editing environment to conform to your programming style. You can also extend your editing environment to handle highly specialized editing needs.
1.4. Designing Programs and Generating Reports
LSE and SCA provide features to help you develop your detailed design and retain it as you move from design to implementation. LSE overviews and SCA reports can retrieve the retained design information.
You can also use LSE and SCA to extract detailed design information from existing source files. You can customize LSE and SCA to improve the design information extracted from source files that were not created using the standard LSE templates.
Chapter 2. Getting Started Designing Programs
Routine interfaces
Data types
Algorithms
Routine calls
Structural (modules, routines and their arguments, variables)
Textual (description of data and algorithms in the form of comments or pseudocode)
With DECset, you specify design information in program source files. This is sometimes called embedded program design. You can gradually transform your design into a completed program, retaining design information in comments, or you can set aside the design and create your implementation in a new source file.
You can choose any of the programming languages supported by DECset to express your design. Your implementation can be in the same language as your design or in other languages. DECset can supply extracted design information in a variety of forms, such as LSE templates, HELP text, and hardcopy reports.
LSE to create and modify design information (in comments and pseudocode)
A compiler to check the syntax of your design
A compiler and SCA to transfer design information to an SCA library
LSE overviews, SCA queries, and SCA reports to retrieve design information
The output from the PACKAGE and HELP reports can then assist in further design and development work.
2.1. Entering Design Information with LSE
This section explains the steps for entering design information for a new or existing program. The examples are in C, but the same steps can be applied to designs and programs written in any language supported by DECset. Customer-written compilers, and even some obsolescent compilers, might not support the /DESIGN qualifier. Therefore, refer to the specific compiler's documentation to determine whether it supports the entering of design information. For more detailed information for entering designs, see Chapter 3, "Entering Design Information Using LSE".
Entering design information for a module
Adding design information for a routine
Entering pseudocode
Moving pseudocode to comments
Using overview operations
Generating an implementation from the design
2.1.1. Entering Design Information for a Module
Create a source file with LSE.
Expand the placeholders to get the template for module header comments.
If you are adding design information to an existing source file, get the template by typing the appropriate token name (for the C language, module_level_comments or MLC), then enter the EXPAND (Ctrl/E) command. You can customize the template to match your own source formatting standards by using the LSE TOKEN commands.
/*
**++
** FACILITY: {@tbs@}
**
** MODULE DESCRIPTION:
**
** {@tbs@}
**
** AUTHORS:
**
** {@tbs@}
**
** CREATION DATE: {@tbs@}
**
** DESIGN ISSUES:
**
** {@tbs@}
**
** [@optional module tags@]...
**
** MODIFICATION HISTORY:
**
** {@tbs@}...
**--
*/[{@tbs@} placeholders and delete unnecessary sections. For
example:/*
**++
** FACILITY: Sample facility 1
**
** MODULE DESCRIPTION:
**
** This is a sample module used to show how to use LSE and SCA to create
** a detailed design.
**
** AUTHORS:
**
** Jane Smith
**
** CREATION DATE: June 27, 1998
**
** KEYWORDS:
**
** Examples, sample design
**
** MODIFICATION HISTORY:
**
** {@tbs@}...
**--
*/2.1.2. Adding Design Information for a Routine
Expand additional placeholders to get a function definition template.
Fill in the header comment block and calling sequence information.
Add the type declarations needed for the function return value and argument types.
#include <stdlib>typedef int integer_matrix[10][10];integer_matrix *matrix_multiply (integer_matrix *left, integer_matrix *right); /* **++ ** FUNCTIONAL DESCRIPTION: ** ** This function computes the matrix product of two integer matrices. ** ** It uses a simple, triple-nested loop, and does not do any checking to ** see if the matrices conform. ** ** FORMAL PARAMETERS: ** ** left: ** The left operand. ** ** right: ** The right operand. ** ** RETURN VALUE: ** ** The result of multiplying the two matrices. ** **-- */ integer_matrix *matrix_multiply (integer_matrix *left, integer_matrix *right)
{ [@block declaration@]...; {@statement@}...; }
| Shows the type declaration used for return value and argument types. |
| Shows the function definition, including function name, return value type, arguments, and their types. |
Note
You have now entered enough design information so you can use SCA to retrieve design information in the form of LSE package definitions, HELP text, and a preliminary INTERNALS report. See Section 2.2, ''Retrieving Design Information'' for more information.
2.1.3. Entering Pseudocode
You can enter your algorithm's design in the form of pseudocode. Pseudocode is a textual description of the actions to be performed by a piece of software. In DECset, pseudocode is bracketed by pseudocode delimiters. By default, these delimiters are « ». They can be customized by using the SET LANGUAGE PSEUDOCODE DELIMIT command.
#include
<stdlib>typedef int integer_matrix[10][10];
integer_matrix *matrix_multiply (integer_matrix *left,
integer_matrix *right);
/*
**++
** FUNCTIONAL DESCRIPTION:
**
** This function computes the matrix product of two integer matrices.
**
** It uses a simple, triple-nested loop, and does not do any checking
** to see if the matrices conform.
**
** FORMAL PARAMETERS:
**
** left:
** The left operand.
**
** right:
** The right operand.
**
** RETURN VALUE:
**
** The result of multiplying the two matrices.
**
**--
*/
integer_matrix *matrix_multiply (integer_matrix *left,
integer_matrix *right)
{
integer_matrix result_matrix;
«Loop over the rows of the left matrix»
return result_matrix;  }
}
| Shows the final source code |
| Uses pseudocode as a loop statement |
| Shows final source code |
2.1.4. Moving Pseudocode to Comments
/*
** Loop over the rows of the left matrix
*/
{@tbs@}
return result_matrix;You
can now fill in the next level of detail of your design as
follows:/*
** Loop over the rows of the left matrix
*/
for (i = 1; i < «matrix size»; i++)
{
«Loop over the columns of the right matrix»
};
return result_matrix;Note that shows a new pseudocode line.
2.1.5. Using Overview Operations
/*
** Loop over the rows of the left matrix
*/
for (i = 1; i < 10; i++)
{
/*
** Loop over the columns of the right matrix
*/
for (j = 1; j < 10; j++)
{
/*
** Compute the inner product of the current row and column
*/
for (k = 1; k < 10; k++)
{
*result_matrix[i][j] =
*result_matrix[i][j] + *left[i][k] * *right[k][j];
}
};
};
return result_matrix;Do an overview operation on by issuing the COLLAPSE
(Ctrl \) command.
/*
** Loop over the rows of the left matrix
*/
for (i = 1; i < 10; i++)
{
«** Loop over the columns of the right matrix ...» };
return result_matrix;
| Shows the retrieved design information that was originally entered as pseudocode in the example in Section 2.1.4, ''Moving Pseudocode to Comments''. |
2.1.6. Completing the Implementation
The source code is complete when all pseudocode placeholders are expanded. (This file is available online in SCA$EXAMPLES:DESIGN_EXAMPLE.C.)
/**
**++
** FACILITY: Sample facility 1
**
** MODULE DESCRIPTION:
**
** This is a sample module used to show how to use LSE and SCA to
** create a detailed design.
**
** AUTHORS:
**
** Jane Smith
**
** CREATION DATE: June 27, 1998
**
** DESIGN ISSUES:
**
** {@tbs@}
**
** KEYWORDS:
**
** Examples, sample design
**
** MODIFICATION HISTORY:
**
** {@tbs@}
**--
*/
#include <stdlib>typedef int integer_matrix[10][10];
integer_matrix *matrix_multiply (integer_matrix *left,
integer_matrix *right);
/**
**++
** FUNCTIONAL DESCRIPTION:
**
** This function computes the matrix product of two integer matrices.
**
** It uses a simple, triple-nested loop, and does not do any checking
** to see if the matrices conform.
**
** FORMAL PARAMETERS:
**
** left:
** The left operand.
**
** right:
** The right operand.
**
** RETURN VALUE:
**
** The result of multiplying the two matrices.
**
**--
*/
integer_matrix *matrix_multiply (integer_matrix *left,
integer_matrix *right)
{
integer_matrix *result_matrix;
int i, j, k;
/*
** Allocate and initialize the result matrix
*/
result_matrix = malloc (i*j);
for (i = 1; i < 10; i++)
{
for (j = 1; j < 10; j++)
{
*result_matrix[i][j] = 0;
}
};
/*
** Loop over the rows of the left matrix
*/
for (i = 1; i < 10; i++)
{
/*
** Loop over the columns of the right matrix
*/
for (j = 1; j < 10; j++)
{
/*
** Compute the inner product of the current row and column
*/
for (k = 1; k < 10; k++)
{
*result_matrix[i][j] =
*result_matrix[i][j] + *left[i][k] * *right[k][j];
}
};
};
return result_matrix;
}2.2. Retrieving Design Information
Transferring design information to an SCA library
Using an SCA keyword query
Generating reports, using the supported languages shown in the example in Section 2.2.3, ''Generating Reports''.
Using LSE packages and help text
2.2.1. Transferring Design Information to an SCA Library
$ CC/ANA/DESIGN/NOOBJECT design_example
$ CREATE/DIR [.scalib] $ SCA CREATE LIBRARY [.scalib] $ SCA SET LIBRARY [.scalib] $ SCA LOAD design_example
Some compilers generate .XREF files that can be converted to .ANA files by means of the SCA IMPORT command. For more information, see the VSI DECset for OpenVMS Guide to Source Code Analyzer.
2.2.2. Using an SCA Keyword Query
You can use an SCA keyword query to find which modules contain keywords. A keyword or keyword phrase associates a concept with a routine or module. These keyword phrases can then be used for indexing. For example, you can label your modules and routines with keyword phrases such as User interface, OpenVMS-specific, AST reentrant, or Examples. Each module or routine can have several keyword phrases associated with it, as many as are applicable.
SCA> FIND CONTAINING (SYMBOL=KEYWORD AND "Examples", SYMBOL=MODULE)
2.2.3. Generating Reports
$ SCA SCA> SET LIB [.scalib] SCA> SET COMMAND LANGUAGE PORTABLE SCA> SET REPORT NAME PACKAGE SCA> SET REPORT LANGUAGE [Ada|BASIC|C|COBOL|FORTRAN|Pascal|PL/I] SCA> SET REPORT HELP_LIBRARY mydisk:[mydir]design_example_help SCA> SET REPORT OUTPUT design_example SCA> REPORT SCA> SET REPORT NAME HELP SCA> SET REPORT OUTPUT design_example SCA> REPORT SCA> SET REPORT NAME INTERNALS SCA> SET REPORT OUTPUT design_example SCA> REPORT SCA> EXIT
$ LSEDIT/NODISP/INIT=SYS$INPUT: design_example.lse SET COMMAND LANGUAGE PORTABLE EXECUTE BUFFER LSE SAVE ENVIRONMENT CHANGES mydisk:[mydir]design_example.env EXIT
$ LIBR/CREATE/HELP design_example_help design_example.hlp
$ DOCUMENT design_example.sdml software.reference PS
2.2.4. Using LSE Packages and Help Text
$ DEFINE LSE$ENVIRONMENT mydisk:[mydir]design_example.env $ LSEDIT new.c
matrix_multiply (
{@left@},
{@right@})matrix_multiply This function computes the matrix product of two integer matrices. It uses a simple, triple-nested loop, and does not do any checking to see if the matrices conform. Returns: pointer to integer_matrix Additional information available: left right
matrix_multiply
left
Type: pointer to integer_matrix
The left operand.You can now fill in the parameter values and continue development.
Chapter 3. Entering Design Information Using LSE
Introductory material
Storing design information in program structure
Storing design information in comments
Using pseudocode to enter design information
3.1. Introduction
3.2. Expressing Design Information Using Program Structure
Names of routines
Return value type of each routine
Names and types of parameters to the routines
Type definitions and data declarations for high-level types and variables that are known at design time
integer_matrix *matrix_multiply (integer_matrix *left, integer_matrix *right)
typedef int integer_matrix[10][10];
Given only this design information (without additional information stored in comments), you can get reports that describe the calling sequence for the routine, including type information. With the addition of comments describing the routine, you can get reports that provide additional explanation of what the routine does, how the parameters are used, and so on.
3.3. Expressing Design Information Using Comments
-- FUNCTIONAL DESCRIPTION:
--
-- Find the arithmetic mean of a list of integers.With LSE, you can easily enter tagged comments into your programs. The templates for LSE include a standard set of comment tags. You can change these tags and add new tags.
Scans comment blocks, looking for tagged comments
Inserts data about those comments into the SCA analysis file
This information can be retrieved by SCA and matched with corresponding identifiers, such as routine names that appear in the code, and be used to generate design reports.
Section 3.3.1, ''Using Tagged Comments'' and Section 3.3.2, ''Associating Comments with Declarations'' explain how to use tagged comments, and how to associate comments with objects.
3.3.1. Using Tagged Comments
Tags are defined within LSE and are saved in an LSE environment file that is read by the compiler. Default tags are in the LSE$SYSTEM_ENVIRONMENT file, where they are also available to compilers. The LSE$ENVIRONMENT logical name must be defined to make your tags available to compilers. There are several types of tags, and the value of these tags is parsed differently depending on the tag type. There are also a number of special tags, each beginning with a dollar sign ($).
The compiler groups comments into comment blocks. Comment blocks are separated either by code (any visible text that is not contained in a comment) or by a blank line (any blank line that is not contained in a comment). Within each comment block, the compiler looks for tagged comments. A tag must be the first text on the line of the comment, not including the comment delimiters. If the tag is not the only text on the line, it must be followed by a tag terminator (a colon or hyphen). Anything after the tag, either on the same line or on subsequent lines, forms the value of the tag, up to but not including the next tag.
There are three types of tagged comments: text, keyword, and structured. The following sections describe these types in detail.
3.3.1.1. Text Comments
3.3.1.2. Keyword Lists
-- FACILITY:
--
-- Sample facility
--
-- KEYWORDS:
--
-- Sample, matrix arithmetic3.3.1.3. Structured Comments
–- FORMAL PARAMETERS:
–-
–- P1:
–- The first parameter
–-
–- P2:  –- The second parameter
–-
–- The second parameter
–-  –- RETURN VALUE:
–- RETURN VALUE:  –-
–- Text about return value
--
–-
–- Text about return value
--
| Shows the required blank line. |
| The parameter name (P1) must be followed by a tag terminator (in this case a colon). |
| Shows the required blank line. |
| The parameter name (P2) must be followed by a tag terminator. |
| Shows the required blank line. |
| The RETURN VALUE tag name must be indented less than (to the left of) P2, and no more than FORMAL PARAMETERS. |
Fully expand the [subtags] and [more-subtags] placeholders produced by the language templates to automatically get the correct formatting.
Two implicit tags are defined for all languages. These are the $UNTAGGED tag and the $REMARK tag. The $UNTAGGED tag is associated with any comment text that occurs at the beginning of a comment block, before the first tag within the comment block.
The $REMARK tag is associated with the first line of text in a comment block, not including any tag names. The PACKAGE report, for example, uses the $REMARK tagged comment for each routine as the description text for the routine.
function function_1 (...)
--
–- This function computes the integer function of the P1,
-- with or without P2s.
--
-- FORMAL PARAMETERS:
...
| These two lines are associated with the $UNTAGGED tag; the first line is also associated with the $REMARK tag. |
3.3.2. Associating Comments with Declarations
You can use comments to associate design information with declarations in your program. Comments that occur in executable portions of your code, where there are no adjacent declarations, are not used for SCA reports.
SCA looks for the closest declaration that is adjacent to the comment block. If there is no adjacent declaration, the comment is associated with the outer-level declaration containing the comment, if any.
int x; /* This comment describes a variable */ int y;
int x; /* This comment describes a variable */ int y;
int x; /* This comment describes a variable */ int y;
This results in the comment being associated with y, because the declaration of y is now closer to the comment than is the declaration of x.
If you leave an ambiguous situation in your code, SCA uses the setting from the LSE SET LANGUAGE COMMENT ASSOCIATION command. (See the entries for SETLANGUAGE commands for more details.)
When you use the /DESIGN=COMMENTS qualifier to compile your source program, the compiler uses your LSE$ENVIRONMENT files and the LSE$SYSTEM_ENVIRONMENT file to determine the setting of the SET LANGUAGE COMMENT ASSOCIATION command. That setting is stored in your analysis data file. SCA performs the comment association, using that setting, at the time you load the file into the SCA library. If you want to change the setting of that qualifier, you must change the setting in LSE, save a new LSE environment file, recompile your program, and load the new analysis data file into SCA.
3.4. Expressing Design Information Using Pseudocode
Pseudocode is easy to write and provides a way to sketch your design ideas. You can convert pseudocode to comments, thus providing a way to preserve design information.
Each compiler that supports the /DESIGN qualifier has a set of conventions describing in what context pseudocode is allowed. Check the documentation for your compiler to learn where pseudocode is allowed in your design. See also Section 4.2.1, ''Compiling Design Information'' for more detail.
/DESIGN=(PLACEHOLDERS,COMMENTS)/ANA
/DESIGN=(NOPLACEHOLDERS,COMMENTS)/ANA
This verifies that no placeholders or pseudocode remain in your source file,and, at the same time, stores information about comments in the analysis datafile.
To create designs for individual routines, expand the LSE placeholders as necessary. Use tagged comments and pseudocode placeholders to contain design information that is still at an abstract level, and use actual code for those portions that are known.
To enter an algorithm or data declaration design, use the ENTER PSEUDOCODE command. See the command dictionary in the VSI DECset for OpenVMS Language-Sensitive Editor/Source Code Analyzer Reference Manual for further information regarding pseudocode commands.
3.4.1. Using Pseudocode in Data Declarations
type record_type is
record
count : integer := 0;
record_name : string({discrete_range}...);
subfield_1 : «A type suitable for subfield 1»;
«subfield 2, which has property x»
[component_declaration]
[variant_part]
end record;
shared_array : array ({discrete_range}...) of record_type;
| LSE generates the {discrete_range}... placeholder. |
| Shows a pseudocode placeholder. This is created using the ENTER PSEUDOCODE (PF1 Space) command, then typing the contents. |
| Shows a pseudocode placeholder, which describes the next field of the record in general terms. |
A pseudocode placeholder typically contains ordinary text, not source code.
It is preferable to fill in as much detail of the design as possible as actual source code.
type record_type is
«a complicated record definition»;However, this format provides little information for your SCA database. For example, in this case, the compiler does not recognize the type definition as a record definition and will not be able to do as much design checking later.
3.4.2. Using Pseudocode in Algorithms
partial_function, -- Used to store the partial
-- results from Murphy's algorithm
final_function : integer; -- Used to store the final result
begin
if «the P2 is present» then
«Use the standard algorithm» else
«Use Murphy’s algorithm»
final_function :=
fix_partial_function(partial_function);
end if;
[statement]...
return final_function;
end function_1;
| Uses pseudocode as the conditional expression in the if statement. |
| Uses pseudocode to represent the entire body of the then clause of the statement. |
| Shows a procedure call. The procedure specification (not shown) must also be present for Ada to recognize this procedure call. With the completed design, you can use SCA to get information about calls to this routine, including this call. |
| Contains an LSE list placeholder. You can use placeholders as part of a design in any context in which they normally appear as the result of an LSE expansion operation. In this example, the [statement]... placeholder remains as a convenience because the algorithm is not yet complete. |
3.4.3. Refining the Design
As the design is refined, you replace pseudocode by more detailed pseudocode,and then by final source code. To preserve the original design information, use the ENTER COMMENT (PF1 B) command. This applies both to the low-level design phase and the implementation phase.
if P2 /= null_P2 then -- P2 is present
Chapter 4. Retrieving Design Information
This chapter provides information on retrieving design information by running standard reports, the options available for each report, and sample outputs for each report.
Using overviews to retrieve design information
Using the OpenVMS compilers and SCA to get design information into an SCA library
Finding keywords
Generating design reports
4.1. Using Overviews to Retrieve Design Information
A powerful feature of the DECset design environment is the ability to display overviews of your code, hiding low-level details to give you a better view of a larger section of code. You can refine the overall results with the LSE NEW ADJUSTMENT command. You can see varying levels of detail when you edit a source file by using the LSE OVERVIEW commands: VIEW SOURCE, COLLAPSE, FOCUS, and EXPAND (see the LSE documentation for more information on these commands). The INTERNALS report uses these LSE commands to produce the body section for each routine.
package body example is
type integer_matrix is array (integer range <>, integer range <>) of
integer;
function matrix_multiply (left, right : in integer_matrix)
return integer_matrix is
-- ++
-- FUNCTIONAL DESCRIPTION:
--
–- This function computes the matrix product of two integer matrices.
--
–- It uses a simple, triple-nested loop, and does not do any checking to
–- see if the matrices conform.
--
-- FORMAL PARAMETERS:
--
–- left:
-- The left operand.
--
-- right:
-- The right operand.
--
-- RETURN VALUE:
--
–- The result of multiplying the two matrices.
--
--
-- result_matrix :
integer_matrix(left'range,right'range(2))
:= (others => (others => 0));
begin
-- Loop over the rows of the left matrix
--
outer_loop: for i in left'range loop
-- Loop over the columns of the right matrix
--
middle_loop: for j in right'range(2) loop
-- Compute the inner product of the current row and column
--
inner_loop: for k in left'range(2) loop
result_matrix(i,j)
:= result_matrix(i,j) + left(i,k) * right(k,j);
end loop inner_loop;
end loop middle_loop;
end loop outer_loop;
return result_matrix;
end matrix_multiply;
end example;«function matrix_multiply (left, right : in integer_matrix) ...»
function matrix_multiply (left, right : in integer_matrix)
return integer_matrix is
«-- FUNCTIONAL DESCRIPTION: ...»
«result_matrix : ...»
«begin ...»
end matrix_multiply;«begin ...» line to see the next level of
detail:function matrix_multiply (left, right : in integer_matrix)
return integer_matrix is
«-- FUNCTIONAL DESCRIPTION: ...»
«result_matrix : ...»
begin
-- Loop over the rows of the left matrix
--
«outer_loop: for i in left’range loop ...»
return result_matrix;
end matrix_multiply;You can continue doing overview operations to selectively display details of the function, and to hide details that are not currently of interest. You can also perform editing functions on overview lines. (See the command dictionary in the VSI DECset for OpenVMS Language-Sensitive Editor/Source Code Analyzer Reference Manual for information on using editing commands with overviews.)
4.2. Transferring Design Information to an SCA Library
Once there is a partial or complete design, you can process the design by using a compiler and SCA.
4.2.1. Compiling Design Information
[NO]COMMENT—Tells the compiler to search inside comments for program design information
[NO]PLACEHOLDERS—Tells the compiler to recognize placeholders (including pseudocode placeholders) as valid program syntax
/DESIGN=(PLACEHOLDERS,COMMENTS)/ANA
/DESIGN=(NOPLACEHOLDERS,COMMENTS)/ANA
This verifies that no placeholders or pseudocode remain in your source file, and, at the same time, stores information about comments in the analysis datafile.
4.2.2. Loading Design Information into an SCA Library
To load analysis data files into an SCA library, use the SCA command LOAD. SCA does not recognize any differences between an analysis data file containing design information and one containing final code information. If a design evolves directly into an implementation, you can use the same arrangement of libraries during design as during implementation.
One for keeping design information
One for holding the implementation information
With SCA, you can use a list of individual SCA libraries as your current virtual library. If a module appears in more than one library in the list, the first instance of the module occludes subsequent instances. Thus,you can set up your SCA libraries so modules being implemented occlude their designs. For those modules still in the design stage, the designs are still available.
You can choose a naming convention at the module level to distinguish between the design of a module and its code. This is necessary because SCA recognizes only one module of a given name in any library.
You can move back and forth, using the SCA command SET LIBRARY.
4.3. Using Keyword Queries
Once the analysis data files containing design information are loaded into an SCA library, you can use SCA queries to retrieve information, as with any other SCA library. The symbol classes defined by SCA specifically for design information are keyword, placeholder, and tag. To get design information, you use these classes with the SYMBOL=construct of the SCA query language.
SCA> FIND CONTAINED_BY(SYMBOL=routine, 'interface' AND SYMBOL=KEYWORD, DEPTH=1)
4.4. Generating Reports
In addition to getting information directly from SCA queries, you can retrieve design information by generating reports. A report covers all or a designated part of your SCA database and presents information in a structured way. You must have both LSE and SCA on your system to generate reports.
You generate reports with the SCA command REPORT. SCA provides four reports that can be customized, or you can add new reports. See Chapter 5, "Customizing Reports" for more information.
The output for each standard report is controlled by the use of report options. The following sections explain how to set report options, and list the available options for each standard report.
4.4.1. Using the Report Commands
SET REPORT
SHOW REPORT
RESET REPORT
REPORT
SET REPORT option-name option-value
This command sets an option value. The options available for each standard report are listed in Section 4.4.10, ''Options for Standard Reports''.You can also obtain a list of all the current option values by using the command SHOW REPORT *.
SCA> SET COMMAND LANGUAGE PORTABLE SCA> SET REPORT NAME PACKAGE SCA> SET REPORT TRACE_MESSAGES ON SCA> REPORT PACKAGE
RESET REPORT option-expression
SCA> RESET REPORT T*
SCA> RESET REPORT *
SHOW REPORT option-expression
SCA> SHOW REPORT T*
SCA> SHOW REPORT *
REPORT [report-name]
This command generates a report. If a SET REPORT NAME command has been given, the report-name is optional; if specified, it must match the name given in the SET REPORT NAME command. When the report is complete, all option values are reset to their default values.
HELP—An OpenVMS Help file generated from your design or code
PACKAGE—An LSE package definition
INTERNALS—A general report that describes your entire design in an organized manner
2167A_DESIGN—A report that produces a document that meets the requirements of the U.S. Defense Department's DOD-STD-2167A Software Design Document
4.4.2. General Report Information
The output of the REPORT command is usually not in its final state. HELP reports must be loaded by the OpenVMS Librarian utility into a help library, and PACKAGE reports must be executed by LSE to produce package definitions. With INTERNALS and 2167A reports, you can produce reports that can be read in three different ways: directly, with DECdocument, or with DIGITAL Standard Runoff.
Because reports perform many SCA queries, they can be time consuming. For this reason, VSI recommends that you use the REPORT command from batch jobs.
Program declarations (modules, routines, types, and variables)
Design information stored in comments
Reports accept a variety of synonymous tags for specific sections of reports. For example, the FORMAL PARAMETERS and FORMAL ARGUMENTS tags are treated as synonyms.
The SCA reports use tags that are included in the system environment file supplied with LSE. You can use the SHOW TAGS command in LSE to show the tags for a particular language.
In general, the tags applicable for an entire file or module are distinct from the tags applicable for a single subroutine. For example, the ABSTRACT tag describes a module, whereas the FUNCTIONAL DESCRIPTION tag describes a subroutine or function. This convention makes it easier for the report tool to distinguish between the two levels of tag information.
$ DEFINE LSE$SOURCE MYDISK:[MYDIR]
This definition tells the report generator to look in the directory MYDISK:[MYDIR] if it is unable to find a source file in the directory where it was compiled.
4.4.3. DOMAIN Option
SCA> FIND (SYMBOL=FILE AND OCCURRENCE=COMMAND_LINE)
Determine an SCA query that represents the specific files.
Perform the query, and give it a name by using the FIND command with the -name option.
Use the query name as the domain for the report.
SCA> SET COMMAND LANGUAGE PORTABLE SCA> FIND -name MYQUERY *matrix* AND SYMBOL=FILE AND OCCURRENCE=COMMAND_LINE SCA> SET REPORT NAME report_name SCA> SET REPORT DOMAIN MYQUERY SCA> REPORT
4.4.4. FILL Option
The FILL option is applied to INTERNALS and 2167A reports. In cases where comment text is copied into the report, the FILL option determines whether the text will be filled. Use FILL OFF if your comments typically contain tables or other formatted output that should not be filled.
4.4.5. DESIGN_EXAMPLE Source File
The source file at the end of Chapter 2, "Getting Started Designing Programs" is used to generate sample output in the following sections. This file is also available online in SCA$EXAMPLES:DESIGN_EXAMPLE.C. Information on customizing reports to get different output is given in Chapter 5, "Customizing Reports".
Description
Sample output
- Table indicating where the information in the output file comes from. These sources are as follows:
Your program structure
Comments in your source files
Report options that you enter when you generate the report
In the case of tagged comments, the table also indicates what tag names are used for the information, and, if applicable, the name of the TPU variable that contains the list of tag names. These TPU variables used for reports all start with sca$report_. In the table, this prefix is replaced by ellipses (...).
The variables and constants referred to in the following sections are defined in the file SYS$LIBRARY:SCA$REPORT_CUSTOMIZATIONS.TPU.
The following is a portion of the DESIGN_EXAMPLE source file used to generate the sample report output:
/*
**++
** FACILITY: Sample facility 1
**
** MODULE DESCRIPTION:
**
** This is a sample module used to show how to use LSE and SCA to
** create a detailed design.
**
** AUTHORS:
**
** Jane Smith
**
** CREATION DATE: June 27, 1998
**
** DESIGN ISSUES:
**
** {@tbs@}
**
** KEYWORDS:
**
** Examples, sample design
**
** MODIFICATION HISTORY:
**
** {@tbs@}
**--
*/
#include <stdlib>typedef int integer_matrix[10][10]; integer_matrix *matrix_multiply (integer_matrix *left, integer_matrix *right);
/* **++ ** FUNCTIONAL DESCRIPTION: ** ** This function computes the matrix product of two integer matrices. ** ** It uses a simple, triple-nested loop, and does not do any checking ** to see if the matrices conform. ** ** FORMAL PARAMETERS: ** ** left: ** The left operand. ** ** right: ** The right operand. ** ** RETURN VALUE: ** ** The result of multiplying the two matrices. ** **-- */
integer_matrix *matrix_multiply (integer_matrix *left, integer_matrix *right)
4.4.6. Creating Online HELP
The HELP report produces an .HLP file that the OpenVMS Librarian utility loads into a standard OpenVMS HELP library. See the VSI OpenVMS Librarian Utility Manual for information on help libraries. See also Section 4.4.10, ''Options for Standard Reports'' for standard report options reference tables.
SCA> SET COMMAND LANGUAGE PORTABLE SCA> SET REPORT NAME HELP SCA> SET REPORT OUTPUT X.HLP SCA> REPORT
$ LIBRARY/HELP/CREATE help-library-name help-file-name
In the previous command, help-library-name is the name of the HELP library that you are creating, and help-file-name is the name of the .HLP file generated by the REPORT command.
$ LIBRARY/HELP/CREATE=KEYWORD:nn help-library-name help-file-name
If the key size you specify is too small, the OpenVMS Librarian displays the following message when you load the .HLP file: "Key XXX name length illegal". To find the key size of an existing library, use the LIBRARY/LIST command to read the maximum key length in the header information.
1 DESIGN_EXAMPLEThe left operand.
3 right Type: pointer to integer_matrix The right operand.
| Callout | Source of Information | TPU Variable |
|---|---|---|
|
|
Program structure—module name, or file name if there is no module name | |
|
|
Tagged comment:
| ...module_descriptions |
|
| Program structure—routine name | |
|
|
Tagged comment:
| ...routine_description_tags |
|
| Program structure—return value type | |
|
| Program structure—parameter name | |
|
| Program structure—parameter type | |
|
|
Untagged comment associated with parameter declaration or
tagged comment:
| ...routine_parameters |
4.4.7. Creating LSE Package Definitions
The PACKAGE report produces an .LSE file, used by LSE to define LSE packages for your program.
SCA> SET COMMAND LANGUAGE PORTABLE SCA> SET REPORT NAME PACKAGE SCA> SET REPORT OUTPUT name.LSE SCA> REPORT
LSE> SET COMMAND LANGUAGE LSE LSE> OPEN FILE package-name.LSE LSE> EXECUTE BUFFER LSE LSE> SAVE ENVIRONMENT CHANGES file_name
LSE NEW PACKAGE DESIGN_EXAMPLELSE SET ROUTINE PARAMETER value
|
Callout |
Source of Information |
|---|---|
|
|
Program structure—module name, or file name if there is no module name |
|
|
Help library file spec comes from HELP_LIBRARY option |
|
|
Program structure—module name, or file name if there is no module name |
|
|
Language names come from LANGUAGES option |
|
|
Program structure—routine name |
|
|
Program structure—routine name |
|
|
$REMARK comment for the routine |
|
|
Program structure—parameter name |
|
|
Program structure—parameter name |
4.4.8. Creating INTERNALS Reports
The INTERNALS report is a comprehensive report on your system, on a module-by-module, routine-by-routine basis. The INTERNALS report extracts information from tagged comments to describe the various aspects of your program. For example, information under the FUNCTIONAL DESCRIPTION tag is used to describe each routine, whereas information under the RETURN VALUE tag is used to describe the return value of each routine. The INTERNALS report also uses the LSE overview mechanism to present the code of each routine in a structured, top-down way.
DOCUMENT—This is the default target. The output is a file suitable for processing by DECdocument. The default output file name is INTERNALS.SDML.
RUNOFF—The output is a file suitable for processing by DIGITAL Standard Runoff (DSR). The default file name is INTERNALS.RNO.
TEXT—The output is a file that you can read directly. The default file name is INTERNALS.TXT.
SCA> SET COMMAND LANGUAGE PORTABLE SCA> SET REPORT NAME INTERNALS SCA> SET REPORT TARGET DOCUMENT SCA> REPORT
$ DOCUMENT INTERNALS.SDML SOFTWARE.REFERENCE destination
- Add a front-matter section to the SDML files you are processing. For example:
$ SCA REPORT INTERNALS
Edit INTERNALS.SDML and add the following text at the beginning of the file, after the<COMMENT>line:<FRONT_MATTER> <TITLE_PAGE> <TITLE>(INTERNALS Report) <ENDTITLE_PAGE> <ENDFRONT_MATTER>
Note
You can supply whatever title you choose in place of "INTERNALS Report".
- Add symbol names to your SDML files.
$ DOCUMENT/GENERATE_SYMBOL INTERNALS.SDML
- Process the resulting file using the SOFTWARE.ONLINE doctype and the BOOKREADER destination, and specify /CONTENTS.
$ DOCUMENT/CONTENTS INTERNALS.SDML SOFTWARE.ONLINE BOOKREADER
An INTERNALS report contains a chapter for each file in the report domain. Each chapter contains the following:Information from module or file level tags, such as ABSTRACT
Sections that describe the global objects of the module, such as imported variables and exported variables
A section on each routine
The format of each routine section is similar to the format of routines in the VMS Run-Time Library Routines Volume. In addition, the body of the routine is presented in a hierarchical fashion, using overviews to hide details at the upper layers, and proceeding until the entire body has been produced.

The following table describes the sources of information for the callouts in Figure 4.1, ''INTERNALS Report Information for Compilation Units Example''.
|
Callout |
Source of Information |
|---|---|
|
|
Program structure—module name, or file name if there is no module name plus declaration class of module. |
|
|
Tagged comment—one section for each module-level tagged comment.? |
|
|
Sections on module-level program structure (imported and exported routines, variables, and types; COMMON blocks, and soon)—name and (if applicable) type information comes from program structure. Object description (for exported objects and module-wide objects) comes from the comment associated with object's declaration. Section title comes from the constant string in SCA$REPORT_CUSTOMIZATIONS.TPU. |
|
|
Program structure—routine name. |

The following table describes the sources of information for the callouts in Figure 4.2, ''INTERNALS Report Information for a Routines Section Example''.
| Callout | Source of Information | TPU Variable |
|---|---|---|
|
|
Program structure—routine name plus declaration class | |
|
| $REMARK comment for routine | |
|
|
Program structure—routine name, parameter names, return value type | |
|
| Program structure—return value type | |
|
|
Tagged comment:
| ...routine_return_value |
|
| Program structure—parameter name | |
|
| Program structure—parameter type | |
|
|
Untagged comment associated with parameter? declaration or tagged comment:
| ...routine_parameters |
|
|
Tagged comment—one section for each routine-level tagged comment? |

The following table describes the sources of information for the callouts in Figure 4.3, ''INTERNALS Report Information for a Body Section Example''.
|
Callout |
Source of Information? |
|---|---|
 |
Body section—Program structure gives the range of lines in the source file that compose the body of the routine. The LSE overview feature is used to display progressively detailed sections of the code. |
|
|
The body of the routine begins with a final source code statement. |
|
|
The second item of the body is pseudocode expanded to a nested for loop. |
|
|
The third and final item of the body is pseudocode expanded with nested pseudocode. Note that the pseudocode description is included in the expansion. |
|
|
A for loop expansion is embedded with the prior left matrix loop and also expands to include an additional pseudocode loop for the right matrix. |
|
|
The right matrix pseudocode is expanded and includes one final pseudocode entry. Note that the pseudocode description is included in the expansion. |
|
|
The final expansion occurs with a nested for loop. |
4.4.9. Creating 2167A Software Design Reports
Use the DECdocument
<INCLUDE>or<ELEMENT>tag for DECdocument reports.Use the .REQUIRE directive for DIGITAL Standard Runoff (DSR) reports.
Merge the output of the REPORT command manually with other text for text reports.
2167A_PROFILE.SDML 2167A_PROFILE.RNO
These profile files use the appropriate commands to include the lower-level files in the report. The SCA$2167A directory also contains stub files for each of those lower-level files. Typically, you create the chapters (other than the requirements chapter) manually, or you use another design tool.
$ SCA REPORT 2167A_DESIGN
The profile files use 2167A_DESIGN as the name of the file to include as Section 4 of the report. If you change the output file name by specifying the OUTPUT option, you must also change the profile file using the new file name.
$ DOCUMENT /CONTENTS SCA$2167A.SDML MILSPEC destination_type
4.4.9.1. Describing 2167A Structure in your Code
The specifications for the DOD-STD-2167A Software Design Report call for a hierarchy of program elements. A design is separated into components, which may be further separated into sublevel components, or units. A unit is the lowest level entity described in the design. For SCA 2167A_DESIGN reports, use tagged comments to represent this structure.
The 2167A_DESIGN report treats each file in your system as a unit of the 2167A design. You specify design information for each unit in a comment block in the source file. Because a 2167A component is a collection of units and subcomponents, the 2167A_DESIGN report maps a set of files into each component. However, it is redundant to duplicate all of the component design information in each file of the component. Instead,select one file as the main design file of the component and put the design information there. The other files in the component contain a single tagged comment that names the component to which they belong.
COMPONENT—Used in each file that you designate as the main design file for a component, either top level or sublevel; the comment names that component.
COMPONENT OF—Used in sublevel components to name the parent of the sublevel component.
UNIT OF—Used in each unit (each file of your system) and names the component to which the file belongs.
Figure 4.4, ''Source Files of Special Tags'' shows a basic layout for a set of source files and how the special tags are used.
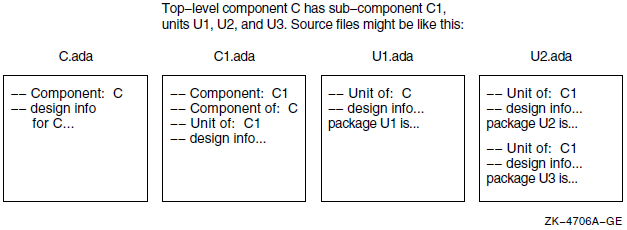
- To set your SCA library to be SCA$2167A, type the following command:
$ SCA SET LIBRARY SCA$2167A
- To create a report, type the following commands:
$ SCA SCA SET COMMAND LANGUAGE PORTABLE SCA> SET REPORT NAME 2167A_DESIGN SCA> SET REPORT OUTPUT mydir:2167a_design SCA> REPORT
- Copy the SDML profile files from SCA$2167A into your directory, as follows:
$ COPY SCA$2167A:*.SDML mydir:
- Define 2167A_DESIGN to point at the report output file you generated, as follows:
$ DEFINE 2167A_DESIGN mydir:2167a_design.sdml
- Invoke DECdocument with a recognized destination_type, such as POST or LINE, as follows:
$ DOCUMENT /CONTENTS 2167A_PROFILE MILSPEC destination_type
4.4.9.2. Retrieving 2167A Structure Information
SCA> FIND COMPONENT AND SYMBOL=TAG
FIND CONTAINED_BY ( -
END = "UNIT OF" AND SYMBOL=TAG, -
BEGIN = "Component 1" AND SYMBOL=KEYWORD, -
DEPTH = 1, -
RESULT = BEGIN))Similarly, you can use queries on the COMPONENT OF tag to find sublevel components of a given component.
The 2167A_DESIGN report uses this information to create the report. It starts by finding the names of all the components of the system.
The report goes through the components one at a time, and writes the component section for each. It finds the units that belong to each component, and writes a unit subsection for each unit.
|
TAGS FOR COMPONENT INFORMATION: | |
|
Tag: |
Description of corresponding section: |
|
COMPONENT DESCRIPTION |
General description of the component |
|
INPUT/OUTPUT DATA |
Input and output data for the component |
|
ALGORITHMS |
Algorithms used by the component |
|
ERROR HANDLING |
Error detection and recovery features |
|
DATA CONVERSION |
Data conversions done by the component |
|
LOGIC FLOW |
Logic flow of the component |
|
REQUIREMENTS ALLOCATION |
Requirements satisfied by this component |
|
TAGS FOR UNIT INFORMATION: | |
|
Tag: |
Description of corresponding section: |
|
UNIT DESCRIPTION |
General description of the unit |
|
INPUT/OUTPUT DATA ELEMENTS |
Input and output data for the unit |
|
LOCAL DATA ELEMENTS |
Data used only in this unit |
|
INTERRUPTS AND SIGNALS |
Interrupts and signals handled by this unit |
|
UNIT ALGORITHMS |
Algorithms used by this unit |
|
UNIT ERROR HANDLING |
Error detection and recovery for the unit |
|
UNIT DATA CONVERSION |
Data conversions done by unit |
|
USE OF OTHER ELEMENTS |
Other elements used by this unit |
|
UNIT LOGIC FLOW |
Logic flow of the unit |
|
DATA STRUCTURES |
Data structures implemented by unit |
|
LOCAL DATA FILES |
Data files or databases used by unit |
|
LOCAL DATABASES |
Same as LOCAL DATA FILES |
|
LIMITATIONS |
Limitations of the unit |
|
REQUIREMENTS ALLOCATED TO THIS UNIT |
Requirements satisfied by this unit |
For Ada programs, these tags can be put into your comment headers automatically by expanding the 2167A placeholder in the header comment for the file.
Because the exact mapping between elements of your program and 2167A items is highly dependent on your particular application and conventions, the 2167A report makes no attempt to use program elements (packages, routines, and so forth.). All information in the report is obtained from tagged comments. However, it is possible to customize reports to use information from your program elements. It is also possible to change the mapping of units to files and components to sets of files. (See Chapter 5, "Customizing Reports" for more information.)
4.4.10. Options for Standard Reports
|
Option Name |
Report Description |
Default Value |
|---|---|---|
|
DOMAIN_QUERY |
Name of query to be used as the domain. |
null string |
|
FILL |
Controls whether comment text is filled. |
ON |
|
OUTPUT |
The output file specification. |
2167A_DESIGN.target-type |
|
TARGET |
Indicates the type of output file to generate. |
SDML (other valid values are TEXT, TXT, RUNOFF, RNO, DSR, DOCUMENT) |
|
DESCRIPTION_INDENT_ |
Gives the width of the first column of two-column tables. |
32 |
|
LIST_STYLE |
Gives the list style to use. |
sca$report_k_list_numbered |
|
LITERAL_ANGLE_BRACKETS |
Controls whether text that contains words in angle brackets, which might otherwise be interpreted as tags, should include the LITERAL tags. ON means to add the LITERAL tags. |
ON |
|
SCA_DEBUG_MESSAGES |
Controls whether to enable debugging messages giving SCA status values. |
OFF |
|
STATUS_MESSAGES |
Controls whether to enable status messages. |
ON |
|
TRACEBACK_FLAG |
Controls whether to enable TPU traceback messages during report execution. |
ON |
|
TRACE_MESSAGES |
Controls whether to enable trace messages generated by calling sca$report_trace_message. |
OFF |
|
USE_SOURCE_SPELLING |
Controls whether the spelling of routine, variable, and type names are taken from the source file or are supplied by SCA. |
ON |
|
Option Name |
Report Description |
Default Value |
|---|---|---|
|
DOMAIN_QUERY |
Name of query to be used as the domain. |
null string |
|
FILL |
Controls whether comment text is filled. |
ON |
|
OUTPUT |
The output file specification. |
INTERNALS.target-type |
|
TARGET |
Indicates the type of output file to generate. |
SDML(other valid values are TEXT, TXT, RUNOFF, RNO, DSR, DOCUMENT) |
|
DECL_CLASS_MODULES |
Controls whether declaration class information appears in report output. |
ON, but overridden for some languages |
|
DECL_CLASS_ROUTINES |
Controls whether declaration class information appears in report output. |
ON, but overridden for some languages |
|
DESCRIPTION_INDENT_ |
Gives the width of the first column of two-column tables. |
32 |
|
INTERNALS_MAXIMUM_ |
Gives the maximum number of lines of source code to be displayed in a single code fragment of an INTERNALS routine body. |
12 |
|
LIST_STYLE |
Gives the list style to use. |
sca$report_k_list_numbered |
|
OVERVIEW_LEVEL |
Controls what depth of detail to display for the body section. |
-1 |
|
ROUTINE_DEPTH |
Controls whether nested routines are reported. For example, a routine_depth of 2 means to report on top-level routines plus the first level of nested routines. |
1 (top-level routines only) |
|
SCA_DEBUG_MESSAGES |
Controls whether to enable debugging messages giving SCA status values. |
OFF |
|
STATUS_MESSAGES |
Controls whether to enable status messages. |
ON |
|
TRACEBACK_FLAG |
Controls whether to enable TPU traceback messages during report execution. |
ON |
|
TRACE_MESSAGES |
Controls whether to enable trace messages generated by calling sca$report_trace_message. |
OFF |
|
USE_SOURCE_SPELLING |
Controls whether the spelling of routine, variable, and type names are taken from the source file or are supplied by SCA. |
ON |
|
Option Name |
Report Description |
Default Value |
|---|---|---|
|
DOMAIN_QUERY |
Name of query to be used as the domain. |
null string |
|
FILL |
Controls whether comment text is filled. |
ON |
|
OUTPUT |
The output file specification. |
HELP.HLP |
|
TARGET |
Indicates the type of output file to generate. |
HLP (the valid values are HELP and HLP) |
|
SCA_DEBUG_MESSAGES |
Controls whether to enable debugging messages giving SCA status values. |
OFF |
|
ROUTINE_DEPTH |
Controls whether nested routines are reported. For example, a routine_depth of 2 means to report on top-level routines plus the first level of nested routines. |
1 (top-level routines only) |
|
STATUS_MESSAGES |
Controls whether to enable status messages. |
ON |
|
TRACEBACK_FLAG |
Controls whether to enable TPU traceback messages during report execution. |
ON |
|
TRACE_MESSAGES |
Controls whether to enable trace messages generated by calling sca$report_trace_message. |
OFF |
|
USE_SOURCE_SPELLING |
Controls whether the spelling of routine, variable, and type names are taken from the source file or are supplied by SCA. |
ON |
|
Option name |
Report Description |
Default value |
|---|---|---|
|
DOMAIN_QUERY |
Name of query to be used as the domain. |
null string |
|
OUTPUT |
The output file specification. |
PACKAGE.LSE |
|
TARGET |
Indicates the type of output file to generate. For details, see the REPORT command description in the VSI DECset for OpenVMS Language-Sensitive Editor/Source Code Analyzer Reference Manual. |
LSE (the valid values are LSE, VMSLSE, PLSE, PORTABLE, and LSEDIT as a synonym for LSE) |
|
LANGUAGES |
The list of languages in which the package definition should be available. |
({language-name1}...) |
|
HELP_LIBRARY |
The file specification used as the help library. |
nullstring |
|
ROUTINE_DEPTH |
Controls whether nested routines are reported. For example, a routine_depth of 2 means to report on top-level routines plus the first level of nested routines. |
1 (top-level routines only) |
|
SCA_DEBUG_MESSAGES |
Controls whether to enable debugging messages giving SCA status values. |
OFF |
|
STATUS_MESSAGES |
Controls whether to enable status messages. |
ON |
|
TRACEBACK_FLAG |
Controls whether to enable TPU traceback messages during report execution. |
ON |
|
TRACE_MESSAGES |
Controls whether to enable trace messages generated by calling sca$report_trace_message. |
OFF |
|
USE_SOURCE_SPELLING |
Controls whether the spelling of routine, variable, and type names are taken from the source file or are supplied by SCA. |
ON |
Chapter 5. Customizing Reports
This chapter provides information on how to customize reports or create new reports.
An introduction to customizing reports
Organizing reports
Processing reports
Modifying a report source file
Changing the default value of an option
Modifying query expressions
Adding new tags and keyword lists
Modifying tag names
Modifying section headers and other fixed text
Deleting information from a report
Customizing 2167A reports
5.1. Introduction
The SCA REPORT command uses TPU in conjunction with the SCA callable interface to generate reports. You can customize the reports or create your own reports (or both) by modifying the TPU source code. The TPU source files for the SCA command REPORT are located in the SYS$LIBRARY directory. For more information on TPU, see the Guide to the DEC Text Processing Utility.
The interface between TPU and SCA is built into LSE. Therefore, you must use LSE for access to the TPU/SCA interface.
5.2. How Reports are Organized
Source files for the reports are in the SYS$LIBRARY directory. Each file has a name in the form SCA$REPORT_module. TPU, with the exception of the file SCA$QUERY_CALLABLE.TPU. The top-level procedure for each report has a name in the form sca$report_report_name. All other routines for the reports have names of the form sca$report_routine_name.
SCA$REPORT_INTERNALS.TPU—Implements the INTERNALS report.
SCA$REPORT_2167A_DESIGN.TPU—Implements the 2167A report.
SCA$REPORT_HELP.TPU—Implements the HELP report.
SCA$REPORT_PACKAGE.TPU—Implements the PACKAGE report.
SCA$REPORT_UTILITIES.TPU—Contains general-purpose routines. It is organized into several sections, with a table of contents at the beginning of the file.
SCA$REPORT_CUSTOMIZATIONS.TPU—Contains variables and constants that provide easy report customization. It also contains comments about customizing reports. It is organized into several sections, with a table of contents at the beginning of the file.
SCA$REPORT_PORTABLE_SYNTAX.TPU—Contains procedures used for processing the portable report commands and defining report options.
Each source file contains header comments summarizing the file's contents, and each procedure within the source file is commented.
5.3. Overview of Report Processing
Issuing SCA queries
Storing query results
Generating report output on the basis of the query results
What queries are issued for the report, in what order the queries are issued, and what the dependencies are between queries.
What information is stored for each query result.
What action routines are invoked to generate the report output. Query result information is passed to the action routines by means of result arrays.
Standard initialization (processes command options, creates buffers needed for report generation, and initializes variables)
Builds a report definition
Generates the report by processing the report definition
Standard cleanup (deletes report buffers, deletes the report definition, deletes result arrays, and so on)
The main procedure for a supplied report is named sca$report_xxx, where xxx is the report name. For example, the main procedure for the INTERNALS report is named sca$report_internals, and it is in the source file SYS$LIBRARY:SCA$REPORT_INTERNALS.TPU.
For each standard report, the report definition is created by the procedure sca$report_build_definition_xxx, where xxx is the report name. The procedures called by the build_definition procedure are defined in the source file SCA$REPORT_UTILITIES.TPU. Information on how to call each of these procedures is found in the procedure's header comments.
A set of utility routines is provided to fetch the results stored for each query. These sca$report_fetch_* routines are also in SCA$REPORT_UTILITIES.TPU, with calling sequence information in the header comments of each procedure. For examples, see the action routines in SCA$REPORT_PACKAGE.TPU.
5.4. Modifying Report Source Files
- Make a local copy of the source file.
$ COPY SYS$LIBRARY:SCA$REPORT_xxx.TPU mydisk:[mydir]
- Edit the local copy to make the desired customizations.
$ LSEDIT mydisk:[mydir]SCA$REPORT_xxx.TPU
- Define a logical name to point to the modified file.
$ DEFINE SCA$REPORT_xxx mydisk:[mydir]SCA$REPORT_xxx
- Generate a report from SCA.
$ SCA REPORT report-name
5.5. Changing the Default Value of an Option
Each report option is represented by a TPU variable with the name sca$report_option_xxx. The option name is xxx. For example, the TPU variable corresponding to the overview_leveloption is sca$report_option_overview_level. The option variables are defined and initialized to their default values in the option definition procedure for each report.
sca$report_add_valid_option ('overview_level', -1, '');sca$report_add_valid_option ('overview_level', 0, '');In this example, you changed the default value of the overview_level option from –1 to 0.
To use the modified file, follow the procedure described in Section 5.4, ''Modifying Report Source Files''.
5.6. Modifying Query Expressions
The query expressions issued by the standard reports are defined as string constants in SCA$REPORT_CUSTOMIZATIONS.TPU. The constant names begin with sca$report_k_query_. Some query expressions are formed during report execution (for example, queries that include the name of the source file currently being processed). The constant portions of these query expressions are also defined in SCA$REPORT_CUSTOMIZATIONS.TPU.
sca$report_k_query_routine_remark :=
'FIND CONTAINED_BY (@SCA$REPORT_CURRENT_ROUTINE,' +
'SYMBOL=TAG AND "OVERVIEW", DEPTH=1, RESULT=BEGIN)'5.7. Adding New Tags and Keyword Lists
LSE provides a set of standard tag definitions for each language. You can define additional tags by using the DEFINE TAG and DEFINE KEYWORDS commands. To save tag definitions in an environment file, use the SAVE ENVIRONMENT command. To tell the compiler about the tag definitions, define the logical name LSE$ENVIRONMENT to include the environment file (LSE$ENVIRONMENT can be a search list). These tags are then available when compiling programs with the /DESIGN qualifier.
Note that it is the compiler and not SCA that checks the program to ensure that any keywords used are appropriate for a given keyword tag.
SET COMMAND LANGUAGE VMSLSE
DEFINE TAG REQUIREMENTS /LANGUAGE=ADA /TYPE=KEYWORD -
/KEYWORDS=Requirements_list
DEFINE KEYWORDS Requirements_list
"AST reentrant"
"Execution time under 1 millisecond"
"Accepts dynamic strings"
END DEFINETo
save these definitions in an environment file, type the following
commands:LSE> SET COMMAND LANGUAGE LSE LSE> SAVE ENVIRONMENT CHANGES MYDISK:[MYDIRECTORY]MYTAGSThe CHANGES option tells LSE to save only the new definitions that you added during the current editing session. This creates a file called MYDISK:[MYDIRECTORY]MYTAGS.ENV. To have the compilers and LSE use this file, type the following DCL command:
$ DEFINE LSE$ENVIRONMENT MYDISK:[MYDIRECTORY]MYTAGS.ENVYou can now use the /DESIGN qualifier to compile your program and the REQUIREMENTS keyword tag will be recognized in your source file. For example, your source file might contain the following lines:
-- Requirements: -- AST Reentrant, accepts dynamic strings
5.8. Modifying Tag Names
The standard reports do special processing of certain tagged comments. For example, tagged comments that contain the routine description and descriptions of routine parameters are given special treatment for HELP and INTERNALS reports. The tag names for these specially processed comments are given by string constants in SCA$REPORT_CUSTOMIZATIONS.TPU. If you define new tag names,modify these string constants.
DEFINE TAG "RESULT" /TYPE=TEXT /LANGUAGE=language-name
sca$report_routine_return_value :=
'("RETURN VALUE" OR "ROUTINE VALUE" OR "FUNCTION VALUE" OR "RESULT")'The DEFINE TAG command tells the compiler that RESULT is a valid tag name to be recorded in the .ANA file and loaded into the SCA library. Changing the constant definition in the report code modifies report processing to recognize the RESULT tag as receiving special handling for HELP and INTERNALS reports.
5.9. Modifying Section Headers and Other Fixed Text
The text for section headers and other fixed text used within reports is defined as string constants in SCA$REPORT_CUSTOMIZATIONS.TPU.
sca$report_section_variables := 'Module-wide variables'
5.10. Deleting Information from a Report
sca$report_definition_add_option (sca$report_k_option_ignore);
!-------------------------------------------------------------------------!
level 3 - imported types
! attribute - type NAME, location object_name
!
sca$report_definition_add_entry (3, 2, 1, 1);
sca$report_definition_add_label ('imported types entry');sca$report_definition_add_option (sca$report_k_option_ignore);
5.11. Customizing 2167A Reports
Because the relationships between your program design or code and the DOD 2167A Software Design Document are dependent upon policies established at your site,you will probably need to customize the report.
In this section, two simple types of customizations are presented. The first example adds a section to a report. The next example shows how to generate the INPUT/OUTPUT section of a report automatically from data declarations in the code, instead of getting the information directly from tagged comments.
5.11.1. Adding a Section to a 2167A Report
- To add a section called PERFORMANCE CONSIDERATIONS for units, begin by defining a UNIT PERFORMANCE CONSIDERATIONS tag by using the DEFINE TAG command, as follows:
DEFINE TAG "UNIT PERFORMANCE CONSIDERATIONS"/TYPE=TEXT - /LANGUAGE=your_language Add the definition entry for the new section in SCA$REPORT_2167A.TPU. If you want the new section to be added after all the other sections,add the definition entry after the one labelled UNIT REQ ENTRY. If you want it in a different position, add the new definition entry between the sections where you want the new section to appear.
The definition entry appears as follows:!------------------------------------------------------------------------- ! level 3 - unit performance entry ! unit_perf query ! attribute - type TAG_NAME, location tag_name ! attribute - type TAG_TEXT, location tag_text ! attribute - type CONSTANT, location section_label ! sca$report_definition_add_entry (3, 1, 3, 0); sca$report_definition_add_label ('unit performance entry'); ! This dynamic query specifies that the name of the current file ! will be inserted at run-time. ! The variable sca$report_unit_file_name is filled in by the action ! routine for the units entry - it is the file name for the current ! unit. sca$report_add_query_dynamic ( sca$report_k_query_2167a_unit_perf + '"', 'sca$report_unit_file_name', '"'); sca$report_definition_add_info (sca$report_k_info_type_tag_name, sca$report_location_tag_name); sca$report_definition_add_info (sca$report_k_info_type_tag_text, sca$report_location_tag_text); sca$report_definition_add_info (sca$report_k_info_type_constant, sca$report_location_section_label, 'Performance considerations');In the file SCA$REPORT_CUSTOMIZATIONS.TPU, add a query string for your new section, as follows:CONSTANT sca$report_k_query_2167a_unit_perf := 'FIND SYMBOL=TAG AND "PERFORMANCE CONSIDERATIONS" AND FILE=';
You can also modify your LSE templates to make this tag available at an appropriate point in the comment header.
VSI recommends that you use distinct names for tags at the component and unit level. In this case, COMPONENT PERFORMANCE CONSIDERATIONS is an appropriate tag to use at the component level. Because the correct level for section headings is apparent from the context in the report output, it is not necessary to use section headings, although you can do so.
5.11.2. Using Program Code For Report Information
The 2167A design report is based solely on tagged comment text; it does not use your program structure. This section shows how to modify this report to get information about global variables from your program structure, rather than from a tagged comment.
The standard 2167A report gets information about a component's INPUT/OUTPUTDATA ELEMENTS (global variables) from tagged comments. To get this information from your program structure, you need to make several changes in the report definition entry labeled component i/o entry.
FIND SYMBOL=VARIABLE AND OCCURRENCE=DECLARATION AND DOMAIN=MULTI_MODULE -
AND FILE="name.ext"sca$report_k_query_2167a_component_io :=
'FIND SYMBOL=TAG AND "INPUT/OUTPUT DATA" AND FILE=',sca$report_k_query_component_io :=
'FIND SYMBOL=VARIABLE AND OCCURRENCE=DECLARATION AND -
DOMAIN=MULTI_MODULE AND FILE=',sca$report_definition_add_info (sca$report_k_info_type_name,
sca$report_location_object_name);
sca$report_definition_add_info (sca$report_k_info_type_variable_type,
sca$report_location_object_type);
sca$report_definition_add_info (sca$report_k_info_type_source_location,
sca$report_location_source_location);sca$report_definition_add_entity_name ('SCA$REPORT_CURRENT_OBJECT');!-------------------------------------------------------------------------
! level 3 - object description
! attribute - type TAG_NAME, location tag_name
! attribute - type TAG_TEXT, location tag_text
!
sca$report_definition_add_entry (3, 1, 2, 1);
sca$report_definition_add_option (sca$report_k_option_all_occurrences);
sca$report_definition_add_query (sca$report_k_query_object_description);
sca$report_definition_add_info (sca$report_k_info_type_tag_name,
sca$report_location_tag_name);
sca$report_definition_add_info (sca$report_k_info_type_tag_text,
sca$report_location_tag_text);
! Action routine for after query is processed - do comment filtering.
!sca$report_definition_add_action_routine (
'sca$report_do_comment_filter',
sca$report_k_invoke_after_all_entities);! Invoke after all entities - write component section.
!
sca$report_definition_add_action_routine (
'sca$report_do_io_section',
sca$report_k_invoke_after_all_entities);!-------------------------------------------------------------------------
! level 2 - component i/o tag
! component_io query
! attribute - type NAME, location object_name
! attribute - type VARIABLE_TYPE, location object_type
! attribute - type SOURCE_LOCATION, location source_location
! attribute - type CONSTANT, location section_label
!
sca$report_definition_add_entry (2, 1, 4, 2);
sca$report_definition_add_label ('component i/o entry');
! The variable sca$report_CSC_file_name is filled in by a CSC action
! routine - it is the file name for the current CSC.
sca$report_definition_add_query_dynamic (
sca$report_k_query_component_io + '"',
'sca$report_CSC_file_name',
'"' );
sca$report_definition_add_info (sca$report_k_info_type_name,
sca$report_location_object_name);
sca$report_definition_add_info (sca$report_k_info_type_variable_type,
sca$report_location_object_type);
sca$report_definition_add_info (sca$report_k_info_type_source_location,
sca$report_location_source_location);
sca$report_definition_add_info (sca$report_k_info_type_constant,
sca$report_location_section_label,
'Input/output data');
sca$report_definition!add_entity_name ('SCA$REPORT_CURRENT_OBJECT');
! Invoke before query - write header for all component sections.
!
sca$report_definition_add_action_routine (
'sca$report_start_component_sections',
sca$report_k_invoke_before_query);
! Invoke after all entities - write component section.
!
sca$report_definition_add_action_routine (
'sca$report_do_io_section',
sca$report_k_invoke_after_all_entities);
!-------------------------------------------------------------------------
! level 3 - object description
! attribute - type TAG_NAME, location tag_name
! attribute - type TAG_TEXT, location tag_text
!
sca$report_definition_add_entry (3, 1, 2, 1);
sca$report_definition_add_option (sca$report_k_option_all_occurrences);
sca$report_definition_add_query (sca$report_k_query_object_description);
sca$report_definition_add_info (sca$report_k_info_type_tag_name,
sca$report_location_tag_name);
sca$report_definition_add_info (sca$report_k_info_type_tag_text,
sca$report_location_tag_text);
! Action routine for after query is processed - do comment filtering.
!sca$report_definition_add_action_routine (
'sca$report_do_comment_filter',
sca$report_k_invoke_after_all_entities);These tagged comments are typically in the module header comment block.
Each parameter description can be either from within a structured comment (under a subtag that matches the parameter name), or from the untagged comment associated with the parameter declaration.
These tagged comments are typically in the routine header comment block. Tag names on the excluded list (sca$report_excluded_tags constant) and module-level tag names are excluded from this section. Sections are in the same order as the corresponding text appears in the source file.
Final expanded items are marked with the callout figures seen on the left side. A right-side callout shows pseudocode to be expanded.